Decoding vLLM Semantic Router
Over the last couple of months, I have been spending more and more time understanding the newer AI trends from the lens of an engineer than just interacting with them as an end user. The aim is to keep unravelling the layers till I start to recognize common patterns emerging in the industry and unravel this blackbox called AI from my mind! I will keep capturing my notes on this blog, with a list of open questions and topics I am unaware about. Each new entry in the blog will aim to answer an open question from a previous entry.
As part of this effort, I came across a new project called vLLM Semantic Router and spent the weekend reading their research publication. It is a Mixture of Models router, which aims to optimise for performance and cost while maintaining inference accuracy. It is built over Envoy, using External processing extension framework and a classification model to route requests to the most suitable backend models.
This one is right up my alley as I have been spending the last 4 years tinkering with Envoy at Tetrate, especially with the external processing framework in the last weeks.
The cost of reasoning
Before I introduce the actual project, Let’s spend some time understanding the underlying problem. There are many open-weight models currently available in the market(which is an amazing thing), and they all support different configurations. One common configuration is to use Reasoning or not. Reasoning is basically telling the AI model to think about the problem in a step by step way. Figuring out intermediate steps, decomposing the problem before acting on it. This is also known as Chain Of Thought reasoning.
Chain of thought technique is quite powerful, allowing models to tackle complex tasks with improved accuracy. This is great, but it comes at a cost. Reasoning increases the latency of inference and the tokens consumed and generated by these models, in turn increasing the cost of generation.
When to reason?
Reasoning leads to massive improvements in models capabilities to perform complex tasks, but it does lead to a phenomena of overthinking in case of simpler problems. There have been plenty of researches which show evidence that simpler problems don’t actually benefit a lot from reasoning abilities, but we do incur the increased cost of latency and inference from reasoning.
This overthinking brings up the question for us, What problems actually require the reasoning abilities? or quite literally, When to reason?
Consider a simple fact based question, What is the height of Mt. Everest? The simple fact based query which doesn’t require any reasoning can be easily solved using a lightweight LLM model. A reasoning model is an overkill for such simple requests.
Introducing Routers
This problem boils down to routing user queries to appropriate models, with or without reasoning, which can solve the users requests reliably and reduce the costs.
Research experiments such as FrugalGPT and RouteLLM, and commercial router offerings such as Martian and Unify AI build a strong case for smarter routing frameworks for AI requests.
Based on my past experience, my mind drew some parallels with a scheduler. You have a couple of providers, each providing multiple compute resources(models) and you ideally want to send your requests to the compute resource which balances between accuracy, cost and performance. It’s the responsibility of the router(scheduler in our analogy) to figure out based on the request characteristics which resource will best fit the request.
vLLM Semantic Router
vLLM is a powerful inference engine, which allows serving popular open-weight models and has quickly become the industry standard. It comes with a lot of powerful features but lacked the support for a semantic router layer. With the Semantic router, the project aims to help users answer when they should reason, what model to use, and optimise for latency and inference cost while maintaining accuracy.
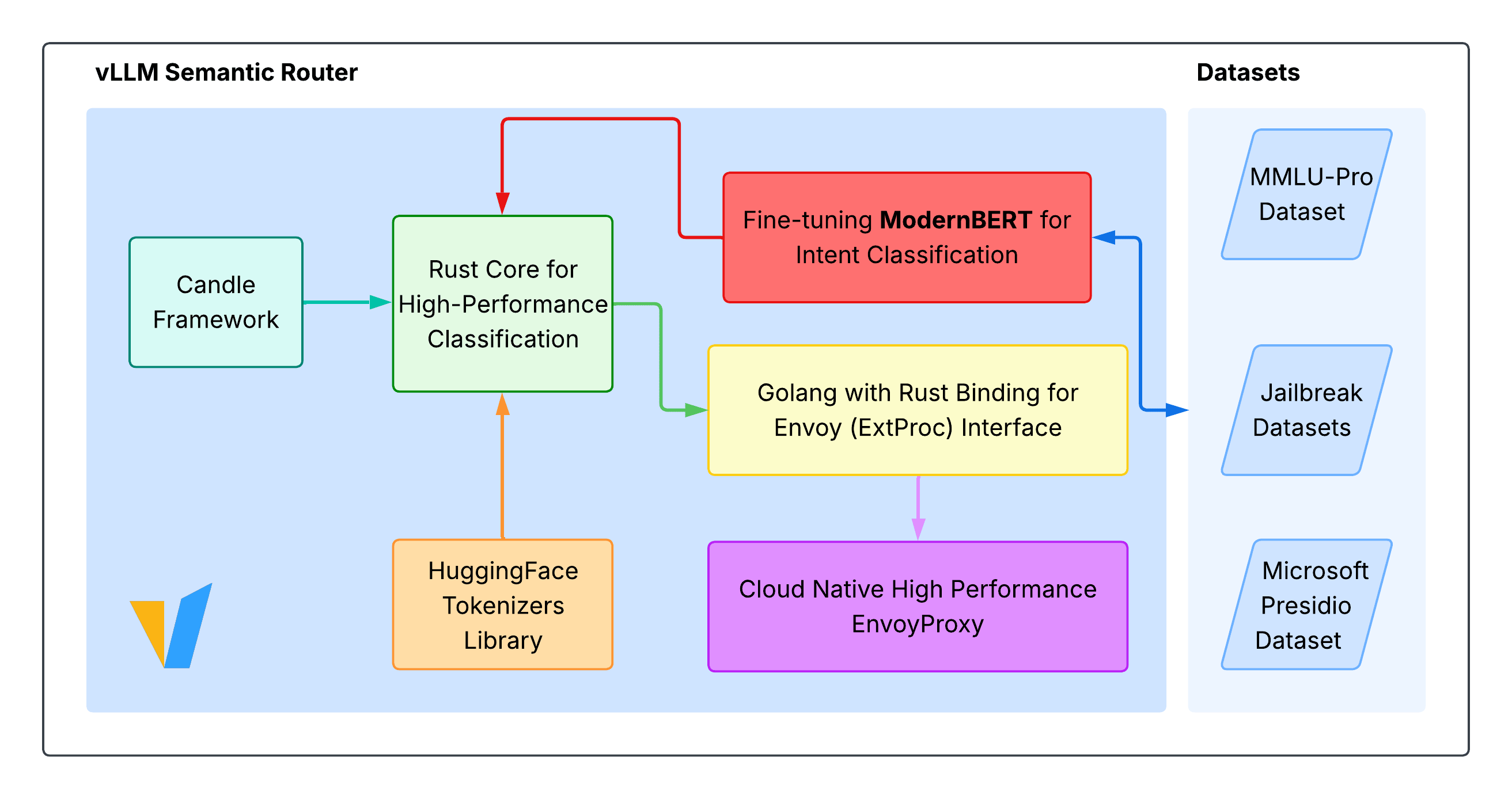
The core idea of the implementation is very simple and has 3 major components:
- A task-complexity classification model
- Classification engine written in Rust
- External Processing server integrating classification engine with Envoy
Task Complexity Classification Model
The router uses a fine-tuned ModernBERT classification model. BERT or ModernBERT(Successor for BERT) models are a specific type of LLM models which are suited for text analysis than text generation. It works great for specific analysis cases, such as classification problem we have at our hand.
For our specific use-case, the project fine-tunes the model on three datasets:
- MMLU-PRO
- Microsoft Presidio
- Jailbreak Datasets
The team has published accuracy results across MMLU-PRO dataset categories against different configurations. I would highly recommend to take a look at these results, which highlight for selective reasoning in case of knowledge based category tasks, the accuracy remains competitive.
Classification Engine
The Classification engine is implemented in Rust, using HuggingFace’s Candle framework. The focus is on efficiency with features like SIMD acceleration, zero-copy tensor operations etc. The engine also does parallel inference for category classification for request, PII detection and Jailbreak attempts. Rust’s thread safety model with various optimisation techniques fits perfect for this use case.
External Processing integration with Envoy
Envoy is one of the most popular cloud-native proxies with a thriving community behind it, serving millions of requests across the internet. With its extensibility frameworks, it fits perfectly for our semantic router use-case.
vLLM Semantic router uses external processing frameworks, which allows the proxy to offboard certain parts of request processing to an external gRPC server. Envoy communicates this gRPC extension framework as part of its filter chain to process the request before proceeding in the filter chain. For this gRPC server, the team opted for Go with Go bindings for Rust classification engine.
Conclusion
The router is able to achieve 10% accuracy improvement (on average, there are some categories where accuracy can take a hit) while reducing the latency and inference costs. The architecture is simple and can be easily run on commodity hardware, and integrates with vLLM making it a great potential optimisation for your AI inference pipelines.
I would suggest to go look at the evaluation results here: https://arxiv.org/abs/2510.08731 to gain a better understanding of their claims
PS: I haven’t replicated these results myself.
Future layers to unravel
Concepts I came across but don’t have any deep knowledge about for now.
- What is BERT and ModernBERT model? What are their use cases and how do they compare with generative models(GPTs) in terms of performance?
- How does Chain Of thought reasoning models are trained?
- What are the inference strategies used by FrugalGPT/RouteLLM?
- What is SIMD acceleration? What kind of instructions benefit the most from it?